Collaboration With Red Hat improving throughput 100x and jitter 500x

This article from Medium by Fatih Nar ( from this link - copied below) shows how multi-cloud networking with network coding by using Steinwurf’s Ramp leads to an improvement of x100 throughput and x500 jitter using Ramp over kubernetes.
Authors:[MIT/Steinwurf: Muriel Medard , Peter Bech , Morten Pedersen] [Red Hat: Fatih E. NAR, Doug Smith, Ali Bokhari, Azhar Sayeed] [Fatih Baltaci CTO at DDosify]
1.0 Introduction
Inthe dynamic landscape of enterprise networking, reliability stands as the cornerstone of success. Timely and dependable data delivery is a critical key performance indicator (KPI) for networks, while any deviation from this, referred to as erasures, can impose significant costs on businesses.
Data erasures occur due to unrecoverable errors in end-to-end transmission and/or excessive jitter (high variations in network performance consistency) in delivery. The associated costs encompass revenue losses, wastage of network resources in futile service attempts, and regulatory penalties for non-compliance.
Traditional methods to enhance reliability often resort to data repetition, which can introduce undesirable latency when applied reactively or incur excessive costs through upfront overprovisioning.

Figure-1(CY2023) Latency Map — Worldwide (Ref: Link-1)
Before we unveil our approach, let’s go through some fundamentals we would build our solution on:
Kubernetes Networking:
Kubernetes (K8s) emerges as a leading container orchestration platform, empowering efficient deployment, scaling, and management of containerized applications, driving modern microservices-based business logic.
At the heart of Kubernetes lies its networking framework, which is pivotal in enabling seamless communication between containers and the outside world. The Container Networking Interface (CNI) specification defines how container runtimes harness various network plugins to endow containers with essential networking capabilities.

Figure-2 Network Interfaces for a K8s Pod
CNI plugins configure container network interfaces, assign IP addresses, set up routes, and offer networking customization for Kubernetes pods. Among these, the Multus CNI plugin stands out, enabling the attachment of multiple network interfaces to a single pod. This capability facilitates intricate networking configurations such as traffic isolation and network segmentation. Multus CNI is the linchpin for high-performance and network-centric workloads in Kubernetes, faithfully adhering to the Kubernetes Network Plumbing Working Group’s standards for multi-networking within Kubernetes.
Forward Erasure Correction:
Forward Erasure Correction (FEC) is used in data communication to enhance reliability and stability, particularly in networks where data retransmission is not feasible or efficient. It’s a technique used to manage the failure of timely packet delivery. The sender adds redundant data to its message, thus allowing the receiver to detect and correct errors without asking the sender for additional data. FEC is especially useful when retransmissions are costly or impossible, such as in broadcasting or communication with long round-trip times between endpoints (e.g., multi-hop routing with packet loss). Here’s how FEC contributes to network stability:
Erasure Correction Without Retransmission: In a typical communication system without FEC, the receiver must ask the sender to retransmit the data if data is corrupted during transmission. This retransmission can lead to increased traffic on the network, potentially causing congestion and instability. By allowing the receiver to correct erasures, FEC reduces the need for retransmissions.
Improved Efficiency in Unstable Conditions: In environments where the signal quality is poor or highly variable (like in wireless networks), FEC can significantly improve the data transmission efficiency. It helps maintain a stable connection even in the presence of interference or signal degradation from phenomena such as fading or blockages.
Bandwidth Utilization: Although FEC increases the amount of data transmitted a priori, that extra data is used to repair erasures, so it is not wasted redundancy. It can lead to more efficient bandwidth use than adding repair post facto, for instance, by repeating packets after erasures occur. This is because the overhead caused by retransmissions in a network without FEC can be much greater when end-to-end reliability mechanisms are used over broadcast or multi-hop networks.
Latency Reduction: In real-time applications like video streaming, online gaming, and autonomous vehicles, waiting for retransmitted data can lead to unacceptable delays. FEC can reduce this latency by correcting erasures on the fly, thus maintaining a smoother and more stable experience.
Scalability in Broadcast Applications: In broadcast applications (like satellite TV), providing individual retransmissions for each receiver is not feasible. FEC allows a single data stream to be reliably received by many users simultaneously, regardless of individual errors in reception.
In this article, we present a new approach to Kubernetes network implementation that capitalizes on the structural maturity and control offered by Multus CNI, together with incorporating a new FEC algorithm via an overlay tunnel mesh to steer us to reduced jitter & latency and amplified bandwidth for containerized workloads (🤞).
2.0 Solution
2.1 RLNC & Steinwurf RAMP
Random Linear Network Coding (RLNC) revolutionizes data packet management by converting them into algebraic components representing portions of multiple packets. This approach fundamentally shifts the paradigm of data delivery, offering a stark contrast to conventional FEC algorithms.

Figure-3 RLNC FEC vs Traditional FEC
In traditional scenarios without RLNC, there’s a stringent requirement to send or receive data packets in a specific sequence for the data to be intelligible. However, RLNC breaks away from this limitation. With RLNC, the process involves gathering a sufficient number of RLNC-encoded packets, which, when combined, solve a particular algebraic equation. This transformation results in an FEC algorithm that’s more adaptable, intelligent, and significantly more efficient in data handling.
By taking the superiority of RLNC FEC into action, Steinwurf has built the RAMP solution, which can upgrade network capabilities and be applied at the application layer to dramatically improve the whole network’s reliability, latency, and bandwidth usage.
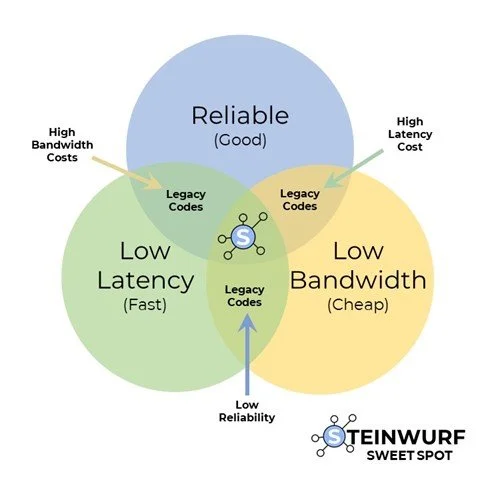
Figure-4 FEC Solution Approaches
RAMP is uniquely designed and implemented as an RLNC FEC approach that does not require a trade-off in any of the three dimensions (latency, reliability, and bandwidth). RAMP has outperformed all available alternatives across traffic types and network fabric patterns.
In addition, the flexibility provided by RAMP makes it possible to combine retransmissions and multi-paths in ways never before possible to form a latency-aware adaptive transport protocol.
Note-1: You can find more details on Steinwurf RAMP solution with FAQ here: [Link-2]
2.2 RAMP CNI
Our minimum viable product (MVP) implementation is a reference concept implementation to run the Steinwurf RAMP solution as a sidecar to a pod (similar to Istio with Envoy however, we do NOT butcher the network performance instead -> we aim to boost it 🚀):
This approach allowed us to integrate our new FEC implementation into our networking stack without modifying the immutable host OS or kernel. The sidecar container can leverage the FEC capabilities, correcting errors for the data transmitted through the overlay tunnel.

Figure-5 Solution & Benchmarking Architecture
In our MVP implementation, Steinwurf RAMP runs as a background process in a sidecar container. Multus CNI creates connectivity over a secondary network, and the Steinwurf RAMP process creates a TUN device over which it asserts its network optimization technology.
Limitations: In the current MVP, one of the major limitations is service discovery. Therefore, all endpoints must be specified in advance.
Future work: A fully automated solution (Level-IV/V Operator Implementation), including installation, configuration, and service discovery, would provide a full mesh between endpoints and automate the discovery of the application endpoints.
Note-2: You can find our testbed implementation git-repo here: [Link-3]
3.0 Benchmarking
With the above-mentioned setup in place, several tests were run to determine the ability of RAMP CNI to recover from packet erasures on the network. The first goal was to see how video quality improves when RAMP CNI is applied to the packet stream.
For that purpose, a video streaming server was deployed in the Mumbai (India) cluster, and a video client in the Ohio (USA) cluster (~ 8,088 miles / 13,017 km separation) was used to stream the video from the Mumbai origin server.
Note-3: You can find our video streaming test app git-repo here: [Link-4]
Once the video stream was established, packet loss was introduced by the long-distance network path. Visual observations clearly showed that the video quality suffered significantly when losses were happening but was only lightly affected when RAMP CNI was enabled on the same lossy network path. In the interest of having quantifiable data, the following set of test cases was also executed:
Identify the impact on UDP traffic when a packet loss happens (up to %10) on the end-to-end network path
Use the iperf3 tool to run a throughput test with UDP traffic between the Ohio and Mumbai clusters
Repeat the test with different packet sizes.
The result of this test case, as shown in the figure below, shows that RAMP CNI could recover effectively from such a significant level of packet erasure, and the test tool did not observe any packet loss.

Figure-6 Benchmark Results — UDP
Identify the impact on TCP traffic when a packet loss happens (up to %10) on the end-to-end network path
Use the iperf3 tool to run a throughput test with TCP traffic between the Ohio and Mumbai clusters
Repeat the test with different packet sizes
The result of this test case, as shown in the figure below, shows that in the absence of RAMP CNI, the TCP throughput was significantly reduced because of the packet loss. However, with RAMP CNI in the network path, the TCP throughput significantly improved, and the receiver received 96% of the traffic sent by the sender.

Figure-7 Benchmark Results — TCP
Identify the impact on jitter for HTTP traffic when a packet loss happens (up to %10) on the end-to-end network path
Install the speed test application in a pod in the Mumbai cluster
Using a browser in the Ohio cluster, run a speed test against the speed test server in the Mumbai cluster
Note-4:You can find our ping/jitter test app git-repo here: [Link-5]
The result of this test case, as shown in the figure below, reflects a 500 times improvement in jitter when the RAMP CNI is enabled on the traffic path.

Figure-8 Benchmark Results — Jitter
Note-5: For custom multi-origin latency measurements towards custom target(s), we kindly recommend using DDosify as easy to use & price/performance outcomes. You can also deploy DDosify on-premise as self-hosted with their k8s helm charts: [Link-6]
4.0 Observations & Closure
The integration of Steinwurf’s RAMP solution with Kubernetes networking, utilizing Multus CNI, presents a significant advancement in network performance for containerized applications with key business benefits:
Enhanced Network Performance: The solution ensures faster data transmission and reduced latency, which is crucial for real-time applications and improving operational efficiency.
Reliable Data Transmission: Steinwurf RAMP provides dependable data transmission, which is essential for maintaining data integrity in distributed systems.
Ease of Configuration: The RAMP CNI offers a user-friendly design that simplifies the setup and management, reducing the learning curve and operational complexity.
Adaptable to Various Conditions: The solution’s versatility allows it to perform consistently across different network conditions and data formats, ensuring stable performance in diverse environments.
Our novel approach represents a significant advancement in the realm of distributed application networking, particularly in the context of executing multi-cloud strategies for large enterprises. It equips businesses with superior performance, heightened reliability, and simplified usability within containerized network landscapes.
As this solution continues to evolve, it is poised to further refine and enhance networking across multiple geographies, ushering in significant improvements in both efficiency and performance at scale.